Logs
Todos nuestros componentes Netcore generan logs estructurados que contienen información sobre la ejecución de los endpoints.
Los logs estructurados son una forma de registrar información en un formato consistente y bien definido, usualmente JSON o algún otro formato de estructura clara (como XML o Protobuf, aunque JSON es el más común). A diferencia de los logs tradicionales en texto plano, que son simplemente líneas de texto libre, los logs estructurados almacenan la información en pares clave-valor (fields), lo que facilita su análisis automático. Nosotros usamos el formato JSON.
Por ejemplo, un log tradicional podría verse así:
2025-08-05 09:43:09 [INF] GT-01119448-2508050004106 VaultService : Generating: 32 random bytes in: base64 format using vault service
Mientras que un log estructurado equivalente podría ser:
{
"@timestamp": "2025-08-05T09:43:09.0192498-04:00",
"level": "Information",
"messageTemplate": "Generating: {bytesCount} random bytes in: {format} format using vault service",
"message": "Generating: 32 random bytes in: base64 format using vault service",
"fields": {
"bytesCount": 32,
"format": "base64",
"traceID": "GT-01119448-2508050004106",
"SourceContext": "VaultService",
}
}
Beneficios:
- Facilitan el análisis automático: Las herramientas de análisis de logs pueden procesar mejor la información estructurada, permitiendo búsquedas precisas.
- Mejor integración con sistemas de monitoreo: Herramientas como ELK Stack, Splunk, Grafana Loki o Datadog funcionan óptimamente con logs estructurados.
- Mayor trazabilidad en entornos distribuidos: En arquitecturas de microservicios, incluir campos como trace_id, request_id o service_name permite rastrear flujos completos de eventos entre servicios.
- Más facilidad para generar alertas o métricas: Los campos estructurados permiten que sistemas de alerta extraigan valores específicos sin tener que parsear texto libre.
En resumen, los logs estructurados mejoran la calidad y utilidad del registro de eventos, haciéndolos más accesibles tanto para humanos como para máquinas.
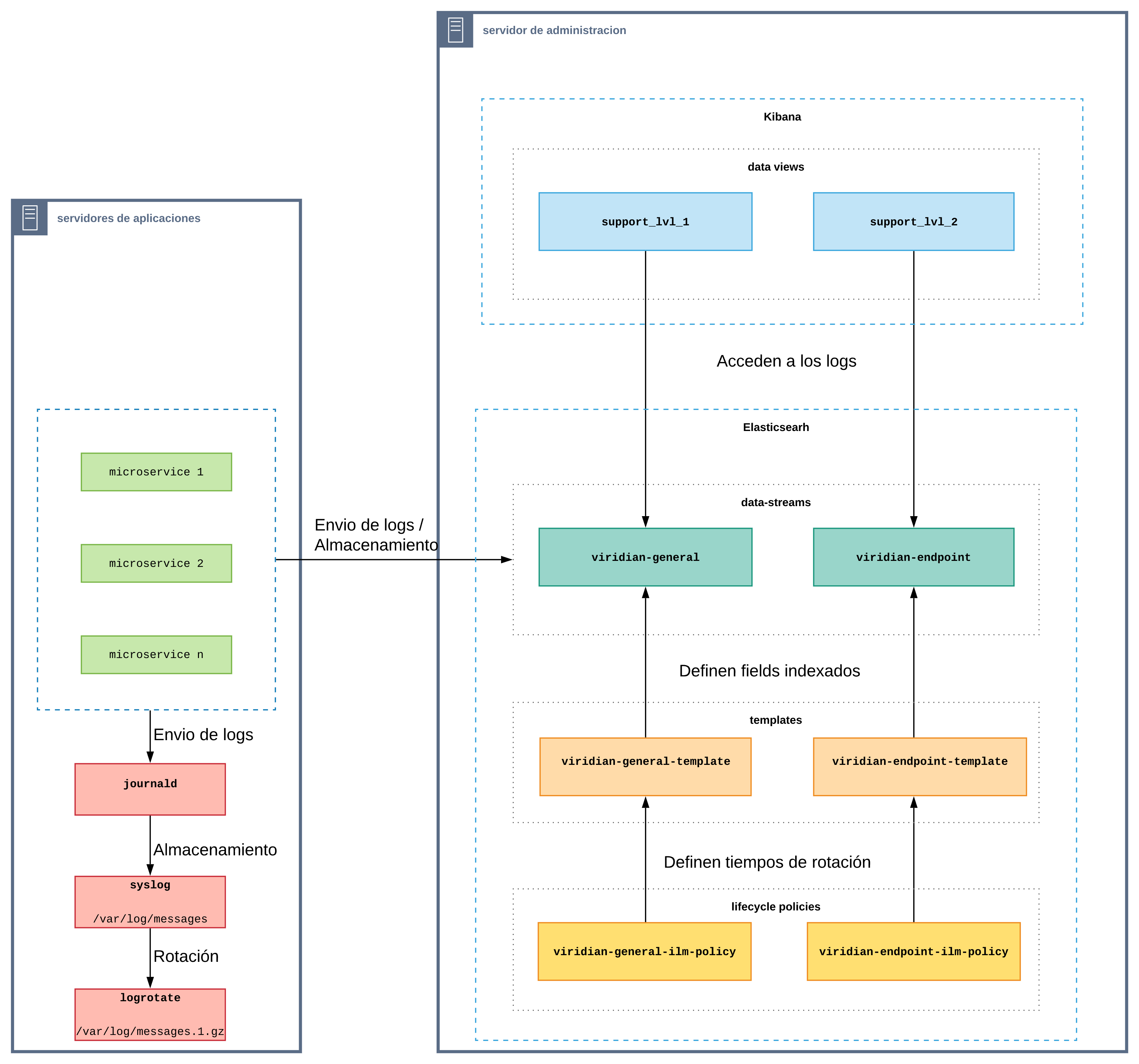
Arquitectura
Serilog
Como libreria para logging usamos Serilog, en conjunto con dos sinks que nos permiten almacenar los logs en distintos formatos.
Sink de consola
Si bien todos los logs que generamos son estructurados, el sink de consola aplica un formato definido a los logs para facilitar su lectura. No loggeamos todo la estructura JSON.
El formato que usamos para mostrar logs en consola es:
{Timestamp:yyyy-MM-dd HH:mm:ss} [{Level:u3}] {traceID,25} {SourceContext,-40} : {Message:lj}{NewLine}{Exception}
Se usan los siguientes fields disponibles en la estructura del log:
- Timestamp
- Level
- traceID
- SourceContext
- Message
- Exception
Sink de Elasticsearch
Este sink mantiene toda la estructura original del log y la envía a Elasticsearch para su almacenamiento.
Tipos de logs
General
Contienen información de toda la ejecución de un endpoint, desde que inicia hasta que termina.
Por ejemplo, estos logs son tipo general:
.
.
.
2025-08-05 09:43:09 [INF] GT-01119448-2508050004106 AuthService : User does not require to use TOTP
2025-08-05 09:43:09 [INF] GT-01119448-2508050004106 DeviceRepository : Entity Device updated
2025-08-05 09:43:09 [INF] GT-01119448-2508050004106 AuthService : Current device access type: FULLACCESS
2025-08-05 09:43:09 [INF] GT-01119448-2508050004106 AuthService : Fullaccess gps mandatory: False and device type: MOBILE
2025-08-05 09:43:09 [INF] GT-01119448-2508050004106 AuthService : Building jwt token for user: 3000004684 - milanesa25 with access type: FULLACCESS
2025-08-05 09:43:09 [INF] GT-01119448-2508050004106 JwtUtil : Building JWT with type: ENCRYPTED, audience: VDB, expire: 08/05/2025 13:45:09
2025-08-05 09:43:09 [INF] GT-01119448-2508050004106 VaultService : Generating: 32 random bytes in: base64 format using vault service
.
.
.
Viendo la estructura del primer log:
{
"@timestamp": "2025-08-05T09:43:09.9304553-04:00",
"level": "Information",
"messageTemplate": "User does not require to use TOTP",
"message": "User does not require to use TOTP",
"fields": {
"SourceContext": "AuthService",
"trnID": "MN-01112864-2508050000173",
"traceID": "GT-01119448-2508050004106",
"sessionID": "GT-01119448-2508050004105",
"endpoint": "Login",
"component": "manager-api",
"componentVersion": "8.33.0",
"server": "BANK-DEV-APP-01",
"logType": "GENERAL"
}
}
Endpoint
Contienen el detalle del request y del response que fueron usados en la ejecución del endpoint.
Por ejemplo, este log es de tipo endpoint:
2025-08-05 09:45:38 [INF] GT-01119448-2508050004111 LogViridianEndpointProducer : Logging endpoint data
Viendo su estructura:
{
"@timestamp": "2025-08-05T09:07:34.9949028-04:00",
"level": "Information",
"messageTemplate": "Logging endpoint data",
"message": "Logging endpoint data",
"fields": {
"endpointData": {
"_typeTag": "LogViridianEndpointTemplate",
"Endpoint": "GetDevices",
"ExecutionTime": 23,
"DateStart": "2025-08-05T09:07:34.971-04:00",
"DateEnd": "2025-08-05T09:07:34.994-04:00",
"CodError": "0",
"DescError": "",
"RequestDataOriginal": null,
"RequestData": {
"userID": "3000004588",
"customerID": 10010951,
"trnID": "MN-01111392-2508050000235"
},
"ResponseData": {
"deviceList": [
{
"id": 15011119,
"deviceStatus": "ENABLED",
"deviceStatusDesc": "Activo",
"accessType": "FULLACCESS",
"accessTypeDesc": "Acceso completo (token)",
"deviceType": "MOBILE",
"deviceOS": "android10",
"deviceInfo": "Redmi - Redmi Note 9 Pro",
"deviceBrowser": "Redmi - Redmi Note 9 Pro",
"lastUse": "05/Ago/2025 09:07:27",
"currentDevice": true,
"dateCreate": "2025-07-21T15:06:49.0000000",
"userCreate": "samuel",
"adminUserCreate": null,
"userUpdate": "samuel",
"adminUserUpdate": null,
"dateUpdate": "2025-08-05T09:07:27.0000000",
"adminDateUpdate": null
}
],
"trnID": "MN-01111392-2508050000235",
"codError": "0",
"descError": null,
"timestamp": "2025-08-05T09:07:34.9945597-04:00"
},
"Instance": "11",
"Exception": null,
"UserId": 3000004588,
"CustomerId": 10010951,
"User": "samuel",
"Customer": "955641",
"DocumentId": "12764087",
"IpAddress": "10.1.101.28",
"Channel": "Mobile",
"Version": "3.5.8",
"Key": ""
},
"logType": "ENDPOINT",
"SourceContext": "LogViridianEndpointProducer",
"endpoint": "GetDevices",
"trnID": "MN-01111392-2508050000235",
"traceID": "GT-01119448-2508050003871",
"sessionID": "GT-01119448-2508050003865",
"component": "manager-api",
"componentVersion": "8.33.0",
"server": "BANK-DEV-APP-01"
}
}
Almacenamiento
Syslog
- Los logs generados por los componentes Netcore, son enviados a consola a través del sink de consola de Serilog.
- Con la configuración
log-driver: journaldde Docker los logs son gestionados por journald. - Con la configuración por defecto de rsyslog instalado en cada servidor, los logs de journald son enviados a syslog y se almacenan en
/var/log/messages - Con logrotate se habilita la rotación del archivo
/var/log/messages, usando la siguiente configuración:
/var/log/messages
{
missingok
daily
compress
copytruncate
rotate 7
sharedscripts
}
Esta configuración nos permite almacenar logs de 7 días en formato de consola, en el mismo servidor.
[adminv@bank-dev-app-01 log]$ cd /var/log/
[adminv@bank-dev-app-01 log]$ ls | grep messages
-rw-------. 1 root root 89281346 Aug 5 11:17 messages
-rw-------. 1 root root 9791628 Aug 5 00:00 messages.1.gz
-rw-------. 1 root root 7194737 Aug 4 00:00 messages.2.gz
-rw-------. 1 root root 6900276 Aug 3 00:00 messages.3.gz
-rw-------. 1 root root 8974026 Aug 2 00:00 messages.4.gz
-rw-------. 1 root root 9587468 Aug 1 00:00 messages.5.gz
-rw-------. 1 root root 9654388 Jul 31 00:00 messages.6.gz
-rw-------. 1 root root 10214641 Jul 30 00:00 messages.7.gz
Elasticsearch
Data streams
Se tiene configurado un data stream por cada tipo de log:
- viridian-general: Almacena logs de tipo general.
- viridian-endpoint: Almacena logs de tipo endpoint.
- Los logs generados por los componentes Netcore, son enviados a elasticsearch a través de su respectivo sink de Serilog.
- Dependiendo del tipo de log, este es almacenado en un data stream diferente.
Lifecycle policies
Se tiene configurado un lifecycle policy por cada data stream:
- viridian-general-ilm-policy: Define el tiempo de retención de los logs de tipo general almacenados en el data stream viridian-general.
- viridian-endpoint-ilm-policy: Define el tiempo de retención de los logs de tipo endpoint almacenados en el data stream viridian-endpoint.
Los logs de tipo general tienen definido un tiempo de retención mas corto comparado con los logs de tipo endpoint, esto se debe a que para dar soporte, es mas valiosa la información de un log de tipo endpoint que un log de tipo general.
Generalmente los tiempos de retención configurados son los siguientes:
- viridian-general-ilm-policy: 30 días.
- viridian-endpoint-ilm-policy: 90 días.
Sin embargo estos valores pueden y deben ajustarse de acuerdo a los requerimiento del banco.
Templates
Elasticsearch es un componente que permite hacer búsquedas sobre fields de un log estructurado, pero estos fields deben estar indexados. Si no se define un template en un data stream entonces por defecto todos los fields quedan indexados y si bien esto puede ser beneficioso ya que podríamos hacer búsquedas por cualquier field, en realidad esto es muy costoso porque se requiere mucho almacenamiento de disco.
Para evitar este problema, definimos un template para cada data stream donde especificamos que fields estarán indexados y por lo tanto disponibles para búsquedas.
- viridian-general-template
| Field | Tipo | Descripción |
|---|---|---|
| @timestamp | date | Timestamp del log |
| level | keyword | Nivel del log |
| message | text | Mensaje del log |
| fields.trnID | text | TrnID de la ejecución del endpoint |
| fields.traceID | text | TraceID de la ejecución del endpoint |
| fields.sessionID | text | SessionID de la ejecución del endpoint |
| fields.endpoint | keyword | Nombre del endpoint |
| fields.component | keyword | Nombre del componente donde se ejecutó el endpoint |
| fields.server | keyword | Servidor donde se ejecutó el endpoint |
- viridian-endpoint-template
| Field | Tipo | Descripción |
|---|---|---|
| @timestamp | date | Timestamp del log |
| level | keyword | Nivel del log |
| message | text | Mensaje del log |
| fields.trnID | text | TrnID de la ejecución del endpoint |
| fields.traceID | text | TraceID de la ejecución del endpoint |
| fields.sessionID | text | SessionID de la ejecución del endpoint |
| fields.endpoint | keyword | Nombre del endpoint |
| fields.component | keyword | Nombre del componente donde se ejecutó el endpoint |
| fields.server | keyword | Servidor donde se ejecutó el endpoint |
| fields.endpointData.ExecutionTime | integer | Tiempo de ejecución del endpoint en ms |
| fields.endpointData.CodError | keyword | Código de error devuelto en la ejecución del endpoint |
| fields.endpointData.User | keyword | Código de usuario o alias del cliente de banca digital para el cual la ejecución del endpoint fue realizada |
| fields.endpointData.Customer | keyword | Código de cliente del cliente de banca digital para el cual la ejecución del endpoint fue realizada |
| fields.endpointData.DocumentId | keyword | Documento de identidad del cliente de banca digital para el cual la ejecución del endpoint fue realizada |
Exploración
Syslog
Como el almacenamiento de logs se lo hace en archivos, la exploración debe hacerse usando comandos de Linux, por ejemplo: vi, less, cat, grep, sed, etc, etc.
No entramos en mucho detalle en este tema ya que consideramos que la exploración de logs debe hacerse usando Kibana.
Kibana
Kibana tiene muchas funcionalidades disponibles pero solo nos enfocaremos en la aplicación Discovery, esta aplicación permite explorar los logs almacenado en Elasticsearch.
La pantalla inicial es esta:
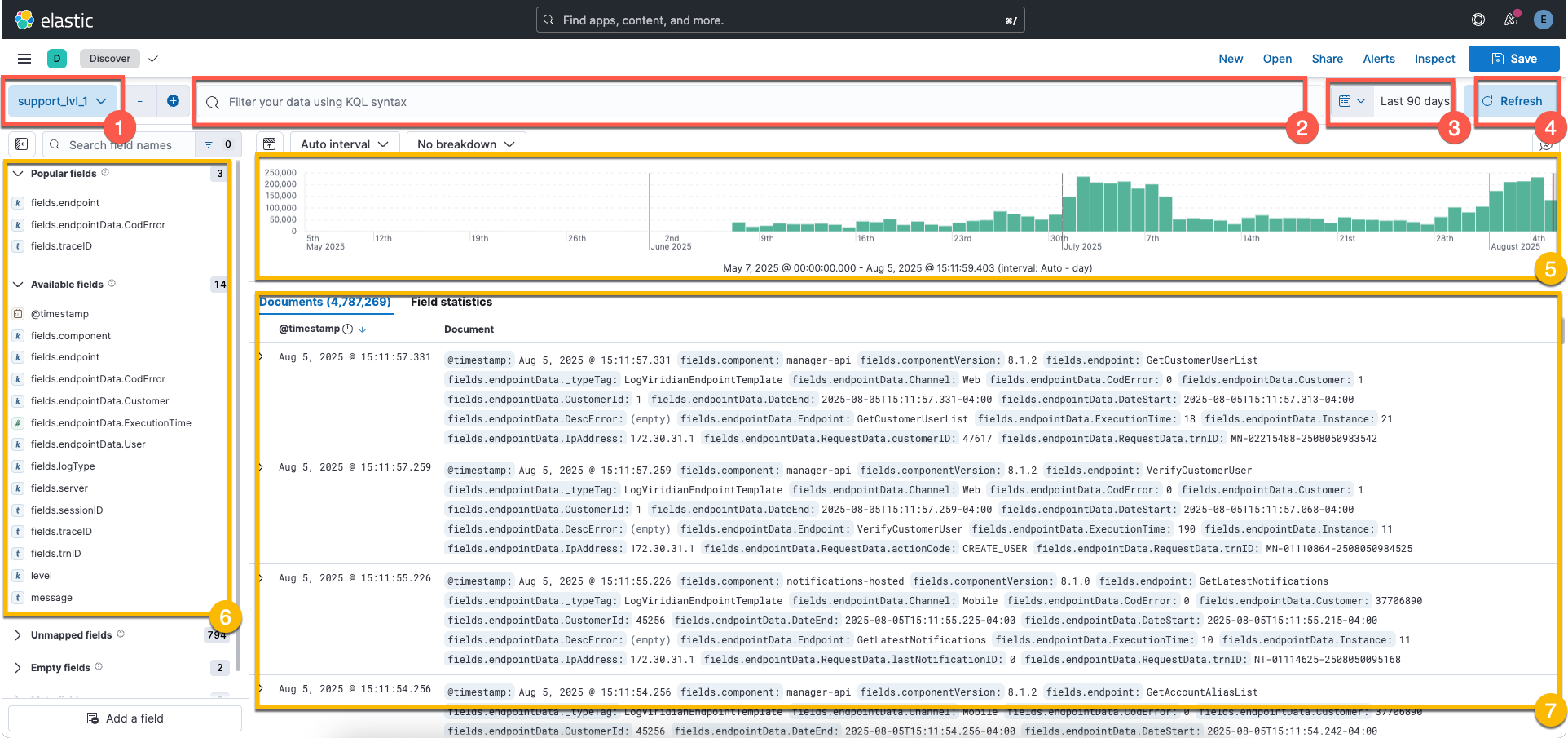
Para explorar los logs se deben seguir los siguientes pasos:
-
Escoger el data view
Existen cuatro data view configurados:
- support_lvl_1: Accede solo al data stream
viridian-endpoint, vale decir que solo explora logs de tipo endpoint. - support_lvl_2: Accede solo al data stream
viridian-endpointyviridian-general, vale decir que explora los logs de tipo endpoint y general. - support_lvl_3: Actualmente no es usado, su comportamiento es similar al de support_lvl_2.
- stats: Actualmente no es usado.
- support_lvl_1: Accede solo al data stream
-
Armar el query
Con los fields disponibles en el template del data stream seleccionado según el data view, se puede armar queries para filtrar la data. Para ver mas información relacionada a la sintaxis de los queries, revisar el siguiente link
-
Seleccionar el rango de fechas
Todos los logs tienen un field
timestampque representa la fecha en la cual el log fue generado, con el seleccionador de rango de fechas se puede filtrar el timestamp de los logs. -
Realizar la búsqueda
Elasticsearch hará la búsqueda de logs que coincidan con la información seleccionada en los puntos 1, 2 y 3.
Los resultados serán desplegados en pantalla:
-
Gráfico con la cantidad de registros encontrados separados por intervalos
El gráfico muestra la cantidad de logs encontrados separados por un intervalo calculado automáticamente. Esto sirve para entender como están distribuidos en el tiempo los logs encontrados.
-
Fields disponibles para agregar al explorador de logs
Se muestran todos los fields disponibles para ser agregados al explorador de logs, en forma de columnas.
-
Explorador de logs
Por defecto muestra todo el contenido estructurado de cada log, lo ideal es primero seleccionar los fields que uno quiere visualizar.
Aca tenemos el ejemplo de un query realizado con sus resultados:
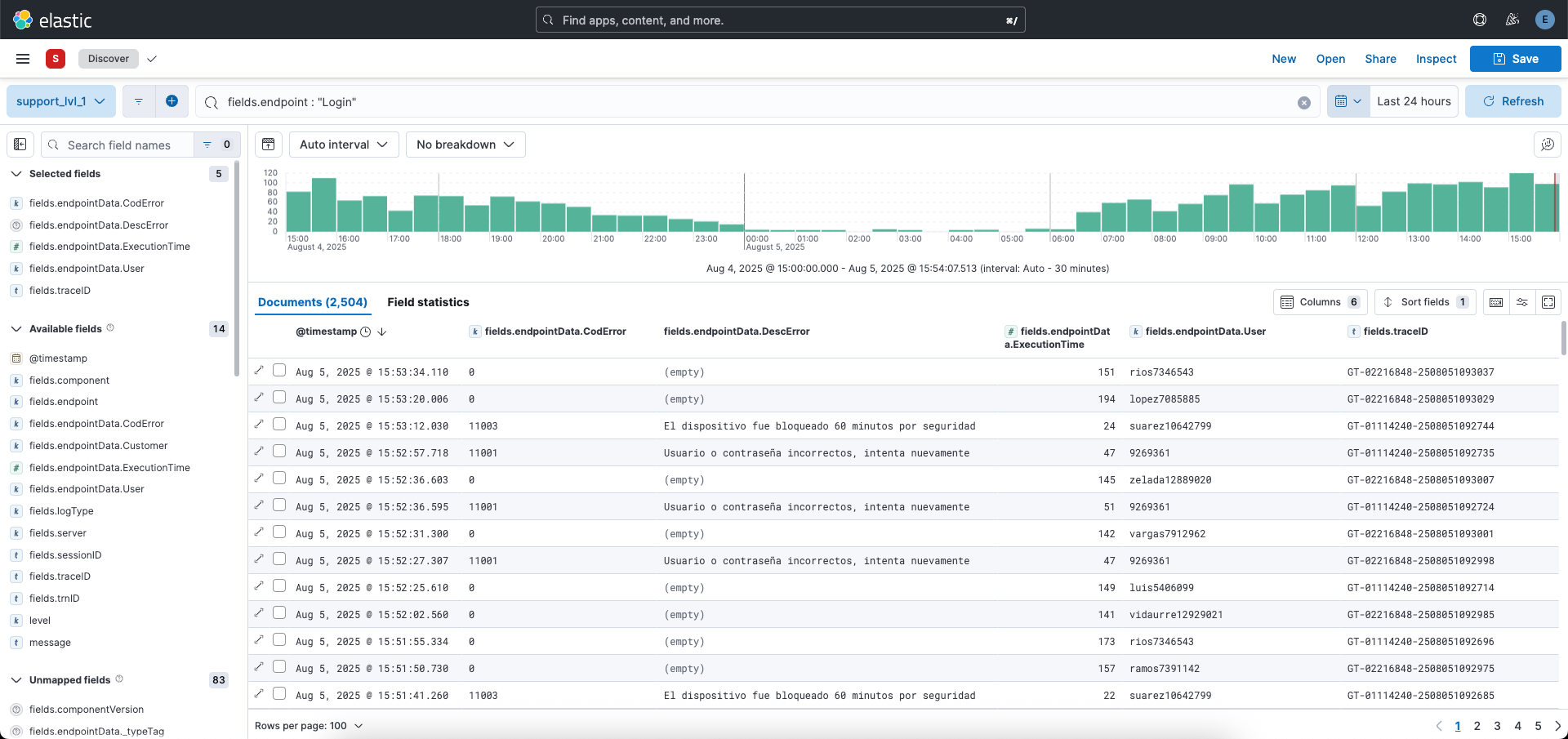
Ejemplos de queries
- Revisar actividad de una persona usando su usuario:
fields.endpointData.User : "torrico6180245" - Revisar actividad de una persona usando su código de cliente:
fields.endpointData.Customer :"45610620" - Revisar endpoints de VIRIDIAN que devuelven un código de error especifico:
not fields.component : "bank-gateway" and fields.endpointData.CodError : "90101" - Revisar endpoints de VIRIDIAN que devuelven un código de error diferente a '0':
not fields.component : "bank-gateway" and not fields.endpointData.CodError : "0" - Revisar endpoints de VIRIDIAN cuya ejecución esta demorando mas de 5 segundos:
not fields.component : "bank-gateway" and fields.endpointData.ExecutionTime > 5000 - Revisar endpoints del banco que devuelven un código de error especifico:
fields.component : "bank-gateway" and fields.endpointData.CodError : "-1" - Revisar endpoints del banco que devuelven un código de error diferente a '0':
fields.component : "bank-gateway" and not fields.endpointData.CodError : "0" - Revisar endpoints del banco cuya ejecución esta demorando mas de 5 segundos:
.component : "bank-gateway" and fields.endpointData.ExecutionTime > 5000